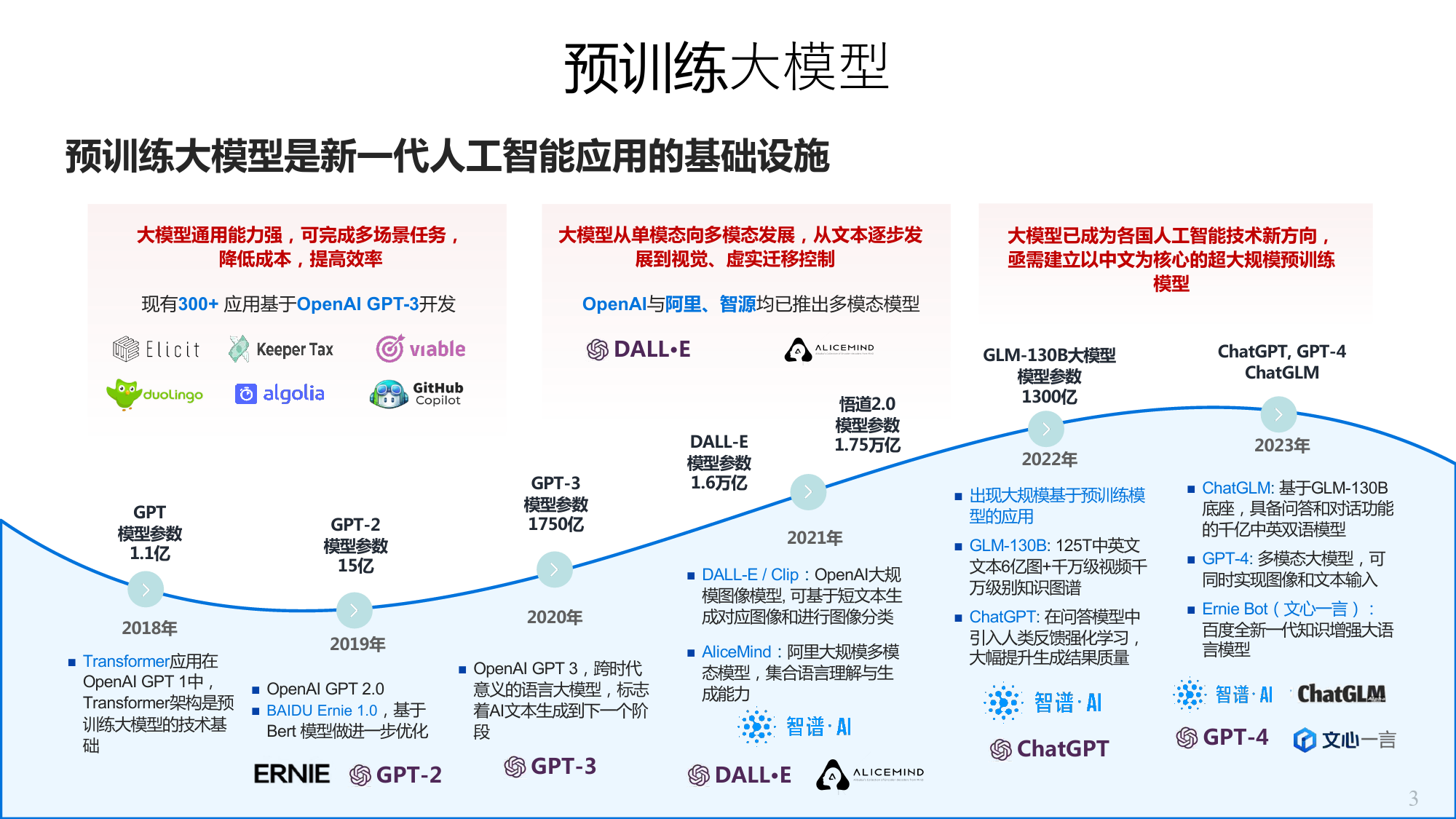
从千亿模型到ChatGPT的⼀点思考唐杰清华⼤学计算机系知识⼯程实验室(KEG)1试试我们的系统•ChatGLM-6B开源,10天10000stars•当天在GitHub的趋势排行第一•过去10天在Huggingface趋势排行第一•开源的训练数据量达到1万亿字符的模型2预训练⼤模型预训练大模型是新一代人工智能应用的基础设施大模型通用能力强,可完成多场景任务,大模型从单模态向多模态发展,从文本逐步发大模型已成为各国人工智能技术新方向,降低成本,提高效率展到视觉、虚实迁移控制亟需建立以中文为核心的超大规模预训练现有300+应用基于OpenAIGPT-3开发OpenAI与阿里、智源均已推出多模态模型模型DALL·EGLM-130B大模型ChatGPT,GPT-4模型参数ChatGLMDALL-E悟道2.01300亿模型参数模型参数2023年1.6万亿1.75万亿2022年nChatGLM:基于GLM-130BGPTGPT-2GPT-32021年n出现大规模基于预训练模底座,具备问答和对话功能模型参数模型参数模型参数型的应用的千亿中英双语模型1750亿nDALL-E/Clip:OpenAI大规1.1亿15亿模图像模型,可基于短文本生nGLM-130B:125T中英文nGPT-4:多模态大模型,可成对应图像和进行图像分类文本6亿图+千万级视频千同时实现图像和文本输入2018年2019年2020年万级别知识图谱nAliceMind:阿里大规模多模nErnieBot(文心一言):nTransformer应用在nOpenAIGPT2.0nOpenAIGPT3,跨时代态模型,集合语言理解与生nChatGPT:在问答模型中百度全新一代知识增强大语OpenAIGPT1中,nBAIDUErnie1.0,基于意义的语言大模型,标志成能力引入人类反馈强化学习,言模型Transformer架构是预着AI文本生成到下一个阶大幅提升生成结果质量训练大模型的技术基Bert模...










发表评论取消回复