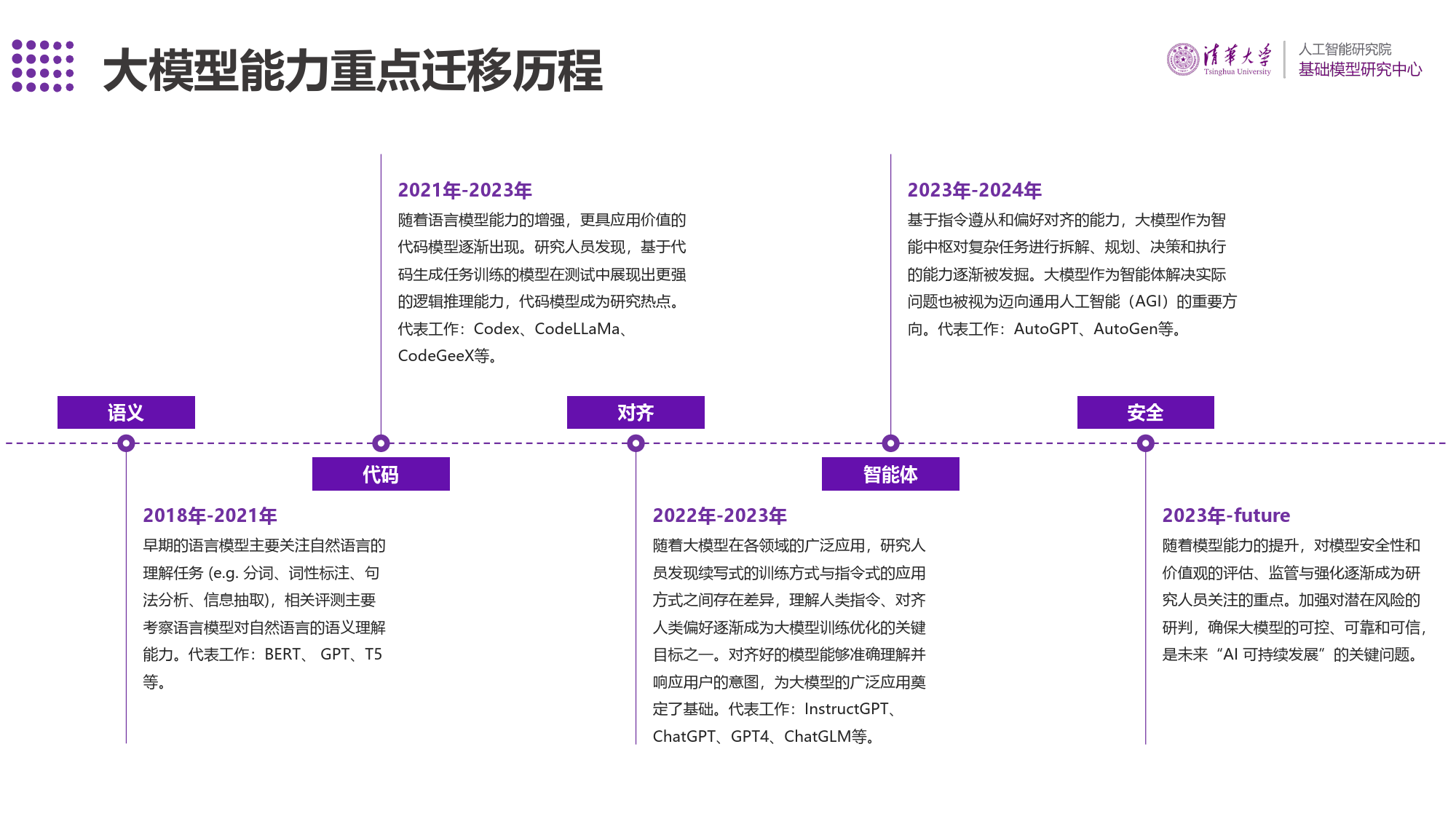
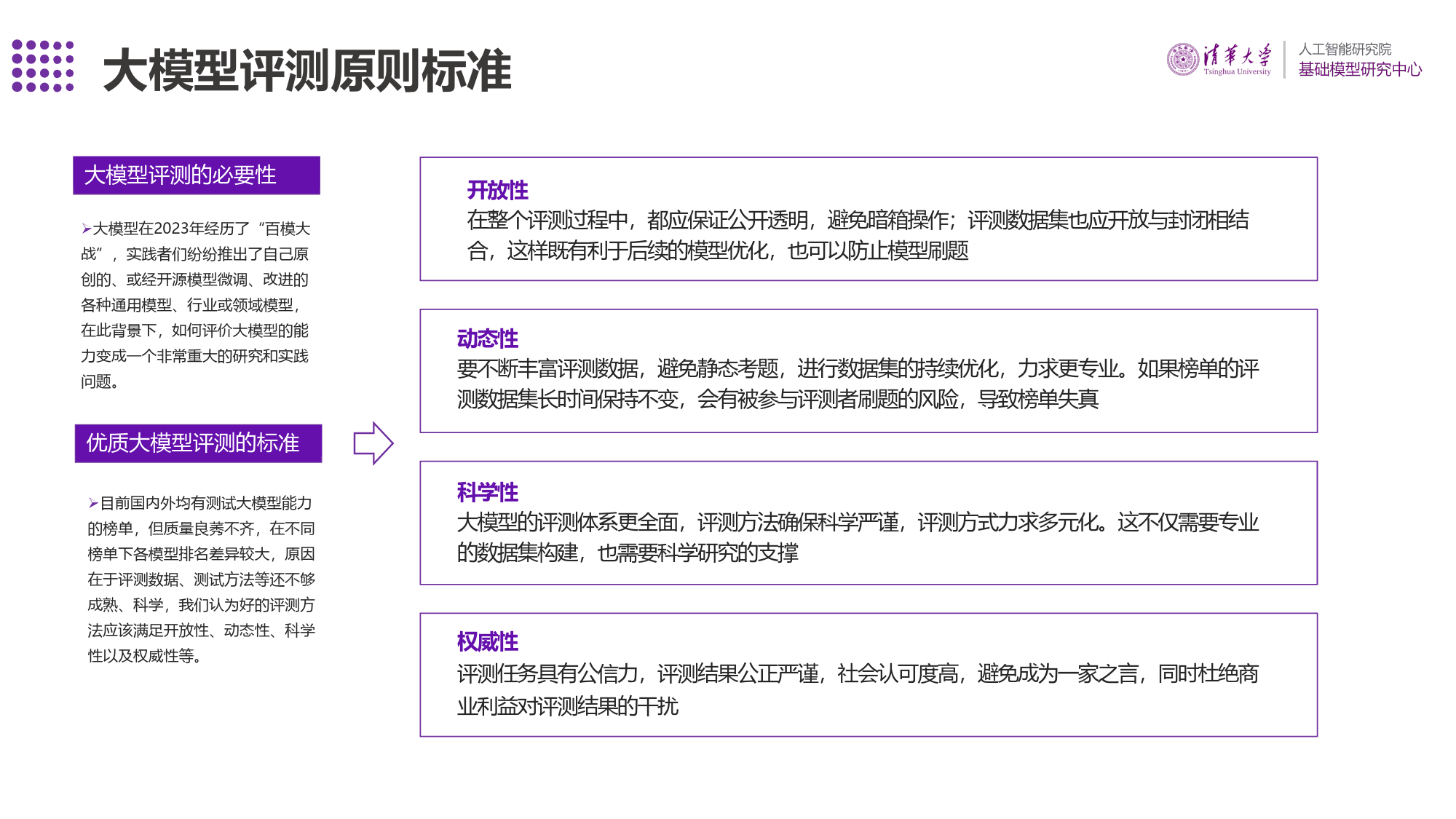
SuperBench大模型综合能力评测报告(2024年3月)SuperBench团队大模型能力重点迁移历程2021年-2023年2023年-2024年随着语言模型能力的增强,更具应用价值的基于指令遵从和偏好对齐的能力,大模型作为智代码模型逐渐出现。研究人员发现,基于代能中枢对复杂任务进行拆解、规划、决策和执行码生成任务训练的模型在测试中展现出更强的能力逐渐被发掘。大模型作为智能体解决实际的逻辑推理能力,代码模型成为研究热点。问题也被视为迈向通用人工智能(AGI)的重要方代表工作:Codex、CodeLLaMa、向。代表工作:AutoGPT、AutoGen等。CodeGeeX等。语义对齐安全代码智能体2023年-future2018年-2021年2022年-2023年随着模型能力的提升,对模型安全性和价值观的评估、监管与强化逐渐成为研早期的语言模型主要关注自然语言的随着大模型在各领域的广泛应用,研究人究人员关注的重点。加强对潜在风险的理解任务(e.g.分词、词性标注、句员发现续写式的训练方式与指令式的应用研判,确保大模型的可控、可靠和可信,法分析、信息抽取),相关评测主要方式之间存在差异,理解人类指令、对齐是未来“AI可持续发展”的关键问题。考察语言模型对自然语言的语义理解人类偏好逐渐成为大模型训练优化的关键能力。代表工作:BERT、GPT、T5目标之一。对齐好的模型能够准确理解并等。响应用户的意图,为大模型的广泛应用奠定了基础。代表工作:InstructGPT、ChatGPT、GPT4、ChatGLM等。大模型评测原则标准大模型评测的必要性开放性在整个评测过程中,都应保证公开透明,避免暗箱操作;评测数据集也应开放与封闭相结大模型C在ha2n0n2e3l:年pr经em历iu了m“百...









发表评论取消回复